

0. 오늘은 기초 프로젝트를 하면서 나오는 내용들에 대해서 적어봤다.
사실 어떻게 하면 프로젝트를 이어갈 수 있을지 부터 내가 짠 코드들 까지....!
잘 하려고 하기보다는, 좀 공부를 한다는 느낌으로 진행했다. 프로젝트는 21일부터 28일까지 총 거의 일주일 기간이었지만 막상 작업해야하는 시간은 굉장히 쪽박했다.
1. 발제자료 선택

이번에 우리팀에서 한 발제는 서울시 부동산 데이터였다. 데이터 기반의 매매와 투자 전략을 요청하는 것. 그것이 이번에 해야할 일이었다.

어떤 걸 해야할까 고민하다가, 작년에 결혼해서 올해 신혼부부이신 조원분이 계셔서 그분을 위한 집을 찾아보는 건 어떨까를 목적으로 분석하기 시작했다.
여기서부터는 이제 내 스스로 좀 분석했던 것, 코드 짜는거 모두 좀 해보려고 한다.
!sudo apt-get install -y fonts-nanum
!sudo fc-cache -fv
!rm ~/.cache/matplotlib -rf
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import matplotlib.font_manager as fmm
from logging import PlaceHolder일단 아주 기본적인 판다스랑 그래프를 만들수 있는 시본과 맷플롯까지! 개인적으로는 다른 것도 갈라고 구글에서 나와서 깔았지만 왜 깔아야하는 지는 좀 어려웠다.
자료를 다운 받은 걸 확인해보니, 기본적으로 자료가 모두, 칼럼이 한글명이고 데이터 타입도 기본적으로 캠프에서 제공하는 걸로 변환시켰다. int 는 정수, string 은 문자, float 는 실수! 아직 기억하고 있다.
column_names = [
'RCPT_YR', 'CGG_CD', 'CGG_NM', 'STDG_CD', 'STDG_NM',
'LOTNO_SE', 'LOTNO_SE_NM', 'MNO', 'SNO', 'BLDG_NM',
'CTRT_DAY', 'THING_AMT', 'ARCH_AREA', 'LAND_AREA', 'FLR',
'RGHT_SE', 'RTRCN_DAY', 'ARCH_YR', 'BLDG_USG', 'DCLR_SE',
'OPBIZ_RESTAGNT_SGG_NM'
]
dtype_dict = {
'RCPT_YR': 'int64',
'CGG_CD': 'string',
'CGG_NM': 'string',
'STDG_CD': 'string',
'STDG_NM': 'string',
'LOTNO_SE': 'string',
'LOTNO_SE_NM': 'string',
'MNO': 'string',
'SNO': 'string',
'BLDG_NM': 'string',
'CTRT_DAY': 'string',
'THING_AMT': 'int64',
'ARCH_AREA': 'float64',
'LAND_AREA': 'float64',
'FLR': 'string',
'RGHT_SE': 'string',
'RTRCN_DAY': 'string',
'ARCH_YR': 'string',
'BLDG_USG': 'string',
'DCLR_SE': 'string',
'OPBIZ_RESTAGNT_SGG_NM': 'string'
}그 뒤로 자료들을 마운트 해줬다. 그게 가장 기본적이니까.
df = pd.read_csv("/content/drive/MyDrive/Python/부동산/2018.csv",encoding='euc-kr',names=column_names, dtype=dtype_dict, skiprows=1)
df2 = pd.read_csv("/content/drive/MyDrive/Python/부동산/2019.csv",encoding='euc-kr',names=column_names, dtype=dtype_dict, skiprows=1)
df3 = pd.read_csv("/content/drive/MyDrive/Python/부동산/2020.csv",encoding='euc-kr',names=column_names, dtype=dtype_dict, skiprows=1)
df4 = pd.read_csv("/content/drive/MyDrive/Python/부동산/2021.csv",encoding='euc-kr',names=column_names, dtype=dtype_dict, skiprows=1)
df5 = pd.read_csv("/content/drive/MyDrive/Python/부동산/2022.csv",encoding='euc-kr',names=column_names, dtype=dtype_dict, skiprows=1)
df6 = pd.read_csv("/content/drive/MyDrive/Python/부동산/2023.csv",encoding='euc-kr',names=column_names, dtype=dtype_dict, skiprows=1)
df7 = pd.read_csv("/content/drive/MyDrive/Python/부동산/2024.csv",encoding='euc-kr',names=column_names, dtype=dtype_dict, skiprows=1)이렇게 따로 내 드라이브에서 저장한 자료들을 불러왔다. 이제 이게 없으면 안되는 거니까. 일단 의뢰인의 조건을 코드를 짜기 전에 한번 짜봤다.
#의뢰인의 조건에 맞는 서울시 내의 건물을 찾아봅니다.
##필수 조건 목록 (2024년도 데이터 기준)
###건물 유형 : 아파트 V
###건물 면적 : 66이상 132 이하
###거래 금액 : 15억 이하
##추가 조건 목록
###새로운 권역구 지정
####동남권(서초구, 강남구, 송파구, 강동구) | 서북권(은평구,서대문구,마포구)
###층수 : 9층 이상
###건축연도 : 10년 이하 혹은 5년 이하(준신축 ~ 신축)
###선호 브랜드
####힐스테이트, 자이, 이편한세상, 롯데캐슬, 현대, 아이파크 (네임밸류 브랜드 선호)
##의뢰인의 목적
###거주를 위한 목적을 원함
###가족의 형태 : 신혼부부
###대게는 직장과 가까우면서, 아직 아이 계획은 없기에 서울의 유흥거리가 있는 동네를 선호
###나이대 30대 초반, 젊은 부부이게 조원분이 제시한 것. 그 전에 가장 중요한게 있는데 '동남권 | 서남권'이라고 적혀있는게 보이는가? 이게 중요하다. 우리가 가지고 있는 컬럼으로는 알 수 없는 조건이기 때문이다. 그래서 새롭게 지정해야하는데 그 자료를 다음 사이트에서 가져왔다.
서울도시공간포털 : 도시계획체계>서울생활권계획
지역생활권 116 일상적인 활동이 이루어지는 공간 범위로 인구 10만 명 내외의 3~5개동으로 구성 지역자원의 활용과 연계, 생활거점의 조성, 주거환경의 개선 등 종합적 주민합의계획 지역의 이슈
urban.seoul.go.kr
기본적으로 책자를 가지고 오기도 했지만, 서울에서 지역균형발전을 위해서 총 5개의 구역으로 나눈다고 한다. 그래서 다음과 같은 새로운 칼럼을 가져왔다.
area_dict= {
"서초구": "동남권", "강남구": "동남권", "송파구": "동남권", "강동구": "동남권",
"은평구": "서북권", "서대문구": "서북권", "마포구": "서북권",
"종로구": "도심권","중구": "도심권","용산구": "도심권",
"성동구": "동북권","광진구": "동북권","동대문구": "동북권","중랑구": "동북권","성북구": "동북권","강북구": "동북권","도봉구": "동북권","노원구": "동북권",
"강서구": "서남권","양천구": "서남권","구로구": "서남권","금천구": "서남권","영등포구": "서남권","동작구": "서남권","관악구": "서남권"
}
df7["area_dict"] = df7['CGG_NM'].map(area_dict)조원분이 짜주신 칼럼이었는데, 정말로 도움이 많이 됐다! 이걸 따르면 이제 맨 뒤에 area_dict 가 새로 생기게 되는 것이다!
##의뢰인 필수 목록 중 1개 [아파트] 만 필터링
##46027 rows × 21 columns
AP1 = df7[df7['BLDG_USG'] == '아파트']
##아파트 조건중에서 일단은 결측치를 확인한다.
###그 중에서 중요한 칼럼인 CGG_NM(자치구명)의 결측치를 확인한다.
AP1.isnull().sum()
###CGG_NM(자치구명)의 결측치를 확인해본다.
####서울시 미아동 확인 - 코드 26230
AP1[AP1.CGG_NM.isna()]
###결측치 제거
AP2 = AP1.drop(73896,axis=0)
##46027 rows × 21 columns
###결측치 제거 확인
AP2.isnull().sum()
###추가 확인
AP2[AP2['CGG_CD'] == 26230]
###직거래 제외 & 취소일자 빼기(거래취소는 안파는 것)
AP3 = AP2[AP2['RTRCN_DAY'].isna()]
AP4 = AP3[(AP3['DCLR_SE'].isna() | (AP3['DCLR_SE'] == '중개거래'))]
AP4
##필수조건 66평 이상 132평 이하
AP5 = AP4[AP4['ARCH_AREA']>=66]
AP6 = AP5[AP5['ARCH_AREA']<=132]
##필수조건 2 15억 이하
AP7 = AP6[AP6['THING_AMT']<=150000]
AP7
###특정지역만 필터링
target_list = ['서초구','강남구','송파구','강동구','은평구','서대문구','마포구']
test = '|'.join(target_list)
AP8=AP7[AP7['CGG_NM'].str.contains(test)]
AP8
###9층 이상의 건물들만 확인
AP8.info() ##--> FLR 는 문자열이므로 정수형 치환
###문자열 -> 정수형으로 치환
AP8['FLR'] = AP8['FLR'].astype(int)
##다시확인
AP8.info()
###9층 이상의 건물 구하기
AP9 = AP8[AP8['FLR']>=9]
AP9
###건축년도 준신축 ~ 신축 ()
####1. 신축 구하기 (5년, 2024-2019)
AP9.info() ##--> FLR 는 문자열이므로 정수형 치환
###문자열 -> 정수형으로 치환
AP9['ARCH_YR'] = AP9['ARCH_YR'].astype(int)
##2016~2019년 준신축~신축
AP10 = AP9[AP9['ARCH_YR']>=2016]
AP11 = AP10[AP10['ARCH_YR']<=2019]
AP11
AP11.drop_duplicates(['BLDG_NM'])
##고객이 요청한 브랜드가 포함된 모든 데이터
cond=AP11.loc[AP11['BLDG_NM'].str.contains('래미안|힐스테이트|디에이치|푸르|자이|편한|아크로|더샵|롯데캐슬|SK뷰|아이파크|IPARK')]
cond
cond.drop_duplicates(['BLDG_NM'])
##e편한세상 이편한세상 중복 제거
##힐스테이트 암사 힐스테이트 강동 리버뷰 중복 제거
cond2 = cond.replace(to_replace='힐스테이트암사',value='힐스테이트 강동 리버뷰')
cond2.drop_duplicates(['BLDG_NM'])
cond3 = cond2.replace(to_replace='이편한세상신촌(1단지)',value='e편한세상신촌1단지')
cond3.drop_duplicates(['BLDG_NM'])
cond3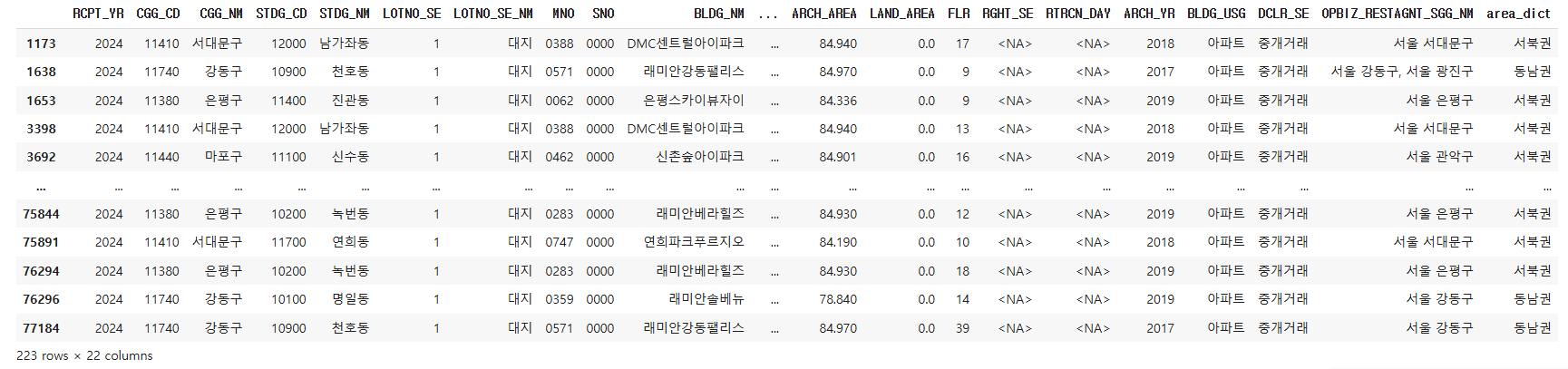
일단은 평균 값도 한번 구해봤다. 개발동끼리!
##특정동 필터링해서 따로 구해보기
##고덕동,남가좌동,녹번동,망원동,명일동,북아현동,불광동,상일동,신수동,아현동,암사동,연희동,응암동,장지동,진관동,천호동,홍은동
###여기서 AP4 란! AP4는 1) 결측치 삭제, 취소물품 삭제, 직거래 삭제, 오로지 아파트
target_list = ['고덕동','남가좌동','녹번동','망원동','명일동','북아현동','불광동','상일동','신수동','아현동','암사동','연희동','응암동','장지동','진관동','천호동','홍은동']
test = '|'.join(target_list)
df_df=AP4[AP4['STDG_NM'].str.contains(test)]
df_df
df_df.drop_duplicates(['STDG_NM'])
#따로 필터링 해보
dd1=df_df[df_df['STDG_NM'] == '고덕동']
dd2=df_df[df_df['STDG_NM'] == '남가좌동']
dd3=df_df[df_df['STDG_NM'] == '망원동']
dd4=df_df[df_df['STDG_NM'] == '명일동']
dd5=df_df[df_df['STDG_NM'] == '북아현동']
dd6=df_df[df_df['STDG_NM'] == '불광동']
dd7=df_df[df_df['STDG_NM'] == '상일동']
dd8=df_df[df_df['STDG_NM'] == '신수동']
dd9=df_df[df_df['STDG_NM'] == '아현동']
dd10=df_df[df_df['STDG_NM'] == '암사동']
dd11=df_df[df_df['STDG_NM'] == '연희동']
dd12=df_df[df_df['STDG_NM'] == '응암동']
dd13=df_df[df_df['STDG_NM'] == '장지동']
dd14=df_df[df_df['STDG_NM'] == '진관동']
dd15=df_df[df_df['STDG_NM'] == '천호동']
dd16=df_df[df_df['STDG_NM'] == '홍은동']
dd17=df_df[df_df['STDG_NM'] == '녹번동']
# 특정 열의 평균 계산
mean_value = dd1['THING_AMT'].mean() ##고덕동
mean_value2 = dd2['THING_AMT'].mean() ##남가좌동
mean_value3 = dd3['THING_AMT'].mean() ##망원동
mean_value4 = dd4['THING_AMT'].mean() ##명일동
mean_value5 = dd5['THING_AMT'].mean() ##북아현동
mean_value6 = dd6['THING_AMT'].mean() ##불광동
mean_value7 = dd7['THING_AMT'].mean() ##상일동
mean_value8 = dd8['THING_AMT'].mean() ##신수동
mean_value9 = dd9['THING_AMT'].mean() ##아현동
mean_value10 = dd10['THING_AMT'].mean() ##암사동
mean_value11 = dd11['THING_AMT'].mean() ##연희동
mean_value12 = dd12['THING_AMT'].mean() ##응암동
mean_value13 = dd13['THING_AMT'].mean() ##장지동
mean_value14 = dd14['THING_AMT'].mean() ##진관동
mean_value15 = dd15['THING_AMT'].mean() ##천호동
mean_value16 = dd16['THING_AMT'].mean() ##홍은동
mean_value17 = dd17['THING_AMT'].mean() ##녹번동
mean_value18 = df_df['THING_AMT'].mean() ##위의 모든 동의 평균
mean_value,mean_value2,mean_value3,mean_value4,mean_value5,mean_value6,mean_value7,mean_value8,mean_value9,mean_value10,mean_value11,mean_value12,mean_value13,mean_value14,mean_value15,mean_value16,mean_value17,mean_value18
int(mean_value),int(mean_value2),int(mean_value3),int(mean_value4),int(mean_value5),int(mean_value6),int(mean_value7),int(mean_value8),int(mean_value9),int(mean_value10),int(mean_value11),int(mean_value12),int(mean_value13),int(mean_value14),int(mean_value15),int(mean_value16),int(mean_value17),int(mean_value18)
일단 분명히 도움이 될만한 자료라고 판단해서 기록만 해두기로 했다.
그래서 종 223개의 아파트 매물을 1차 후보군으로 선정했다. 그러면 이렇게 보면 시세를 모르겠어서 혹시 몰라서 2018~2023년에는 해당 아파트는 각 어땠는지 필터 걸고, 안걸고 여러가지 고려해서 구해봤다.
##권역별 필수 지정(2018~2023)
area_dict= {
"서초구": "동남권", "강남구": "동남권", "송파구": "동남권", "강동구": "동남권", #동남권
"은평구": "서북권", "서대문구": "서북권", "마포구": "서북권", #서북권
"종로구": "도심권","중구": "도심권","용산구": "도심권", #도심권
"성동구": "동북권","광진구": "동북권","동대문구": "동북권","중랑구": "동북권","성북구": "동북권","강북구": "동북권","도봉구": "동북권","노원구": "동북권", #동북권
"강서구": "서남권","양천구": "서남권","구로구": "서남권","금천구": "서남권","영등포구": "서남권","동작구": "서남권","관악구": "서남권" #서남권
}
df["area_dict"]= df['CGG_NM'].map(area_dict)
df2["area_dict"]= df2['CGG_NM'].map(area_dict)
df3["area_dict"]= df3['CGG_NM'].map(area_dict)
df4["area_dict"]= df4['CGG_NM'].map(area_dict)
df5["area_dict"]= df5['CGG_NM'].map(area_dict)
df6["area_dict"]= df6['CGG_NM'].map(area_dict)
##의뢰인 필수 목록 중 1개 [아파트] 만 필터링
bf = df[df['BLDG_USG'] == '아파트']
bf2 = df2[df2['BLDG_USG'] == '아파트']
bf3 = df3[df3['BLDG_USG'] == '아파트']
bf4 = df4[df4['BLDG_USG'] == '아파트']
bf5 = df5[df5['BLDG_USG'] == '아파트']
bf6 = df6[df6['BLDG_USG'] == '아파트']
###직거래 제외 & 취소일자 빼기(거래취소는 안파는 것) ##2018~2020년은 <NAN>만존재
####bf,bf2,bf3 <na> 값만 존재합니다.
aap4 = bf4[(bf4['DCLR_SE'].isna() | (bf4['DCLR_SE'] == '중개거래'))]
aap5 = bf5[(bf5['DCLR_SE'].isna() | (bf5['DCLR_SE'] == '중개거래'))]
aap6 = bf6[(bf6['DCLR_SE'].isna() | (bf6['DCLR_SE'] == '중개거래'))]
aaap1 = bf[bf['RTRCN_DAY'].isna()]
aaap2 = bf2[bf2['RTRCN_DAY'].isna()]
aaap3 = bf3[bf3['RTRCN_DAY'].isna()]
aaap4 = aap4[aap4['RTRCN_DAY'].isna()]
aaap5 = aap5[aap5['RTRCN_DAY'].isna()]
aaap6 = aap6[aap6['RTRCN_DAY'].isna()]
target_list = ['서초구','강남구','송파구','강동구','은평구','서대문구','마포구']
test = '|'.join(target_list)
df_dfa = aaap1[aaap1['CGG_NM'].str.contains(test)]
df_dfb = aaap2[aaap2['CGG_NM'].str.contains(test)]
df_dfc = aaap3[aaap3['CGG_NM'].str.contains(test)]
df_dfd = aaap4[aaap4['CGG_NM'].str.contains(test)]
df_dfe = aaap5[aaap5['CGG_NM'].str.contains(test)]
df_dff = aaap6[aaap6['CGG_NM'].str.contains(test)]
df_dfg = AP8[AP8['CGG_NM'].str.contains(test)]
ap_apa = df_dfa.groupby(['area_dict','CGG_NM'])['THING_AMT'].mean() ##18
ap_apb = df_dfb.groupby(['area_dict','CGG_NM'])['THING_AMT'].mean() ##19
ap_apc = df_dfc.groupby(['area_dict','CGG_NM'])['THING_AMT'].mean() ##20
ap_apd = df_dfd.groupby(['area_dict','CGG_NM'])['THING_AMT'].mean() ##21
ap_ape = df_dfe.groupby(['area_dict','CGG_NM'])['THING_AMT'].mean() ##22
ap_apf = df_dff.groupby(['area_dict','CGG_NM'])['THING_AMT'].mean() ##23
ap_apg = df_dfg.groupby(['area_dict','CGG_NM'])['THING_AMT'].mean() ##24
check_cc = pd.concat([ap_apa, ap_apb, ap_apc, ap_apd, ap_ape, ap_apf, ap_apg], axis=1)
check_cc.columns = [2018, 2019, 2020, 2021, 2022, 2023, 2024] # 연도별 컬럼 이름 지정
cd = check_cc.round(0)
##특정동 필터링해서 따로 구해보기
##고덕동,남가좌동,녹번동,망원동,명일동,북아현동,불광동,상일동,신수동,아현동,암사동,연희동,응암동,장지동,진관동,천호동,홍은동
###여기서 AP4 란! AP4는 1) 결측치 삭제, 취소물품 삭제, 직거래 삭제, 오로지 아파트
target_list = ['고덕동','남가좌동','녹번동','망원동','명일동','북아현동','불광동','상일동','신수동','아현동','암사동','연희동','응암동','장지동','진관동','천호동','홍은동']
test = '|'.join(target_list)
df_df1 = aaap1[aaap1['STDG_NM'].str.contains(test)]
df_df2 = aaap2[aaap2['STDG_NM'].str.contains(test)]
df_df3 = aaap3[aaap3['STDG_NM'].str.contains(test)]
df_df4 = aaap4[aaap4['STDG_NM'].str.contains(test)]
df_df5 = aaap5[aaap5['STDG_NM'].str.contains(test)]
df_df6 = aaap6[aaap6['STDG_NM'].str.contains(test)]
df_df7 = AP8[AP8['STDG_NM'].str.contains(test)]
##피벗
pivot_tablez = pd.pivot_table(df_df1,index=['area_dict','CGG_NM','STDG_NM'],columns='RCPT_YR',values='THING_AMT',aggfunc='mean') ##18
pivot_tablex = pd.pivot_table(df_df2,index=['area_dict','CGG_NM','STDG_NM'],columns='RCPT_YR',values='THING_AMT',aggfunc='mean') ##19
pivot_tablec = pd.pivot_table(df_df3,index=['area_dict','CGG_NM','STDG_NM'],columns='RCPT_YR',values='THING_AMT',aggfunc='mean') ##20
pivot_tablev = pd.pivot_table(df_df4,index=['area_dict','CGG_NM','STDG_NM'],columns='RCPT_YR',values='THING_AMT',aggfunc='mean') ##21
pivot_tableb = pd.pivot_table(df_df5,index=['area_dict','CGG_NM','STDG_NM'],columns='RCPT_YR',values='THING_AMT',aggfunc='mean') ##22
pivot_tablen = pd.pivot_table(df_df6,index=['area_dict','CGG_NM','STDG_NM'],columns='RCPT_YR',values='THING_AMT',aggfunc='mean') ##23
pivot_tablem = pd.pivot_table(df_df7,index=['area_dict','CGG_NM','STDG_NM'],columns='RCPT_YR',values='THING_AMT',aggfunc='mean') ##24
ap_ap1 = df_df1.groupby(['area_dict','CGG_NM','STDG_NM'])['THING_AMT'].mean() ##18
ap_ap2 = df_df2.groupby(['area_dict','CGG_NM','STDG_NM'])['THING_AMT'].mean() ##19
ap_ap3 = df_df3.groupby(['area_dict','CGG_NM','STDG_NM'])['THING_AMT'].mean() ##20
ap_ap4 = df_df4.groupby(['area_dict','CGG_NM','STDG_NM'])['THING_AMT'].mean() ##21
ap_ap5 = df_df5.groupby(['area_dict','CGG_NM','STDG_NM'])['THING_AMT'].mean() ##22
ap_ap6 = df_df6.groupby(['area_dict','CGG_NM','STDG_NM'])['THING_AMT'].mean() ##23
ap_ap7 = df_df7.groupby(['area_dict','CGG_NM','STDG_NM'])['THING_AMT'].mean() ##24
check_ap = pd.concat([ap_ap1, ap_ap2, ap_ap3, ap_ap4, ap_ap5, ap_ap6, ap_ap7], axis=1)
check_ap.columns = [2018, 2019, 2020, 2021, 2022, 2023, 2024] # 연도별 컬럼 이름 지정
cd2 = check_ap.round(0)
##아파트를 한번만 더 필터링
df_APT_filtered = df_df1[df_df1['BLDG_NM'].str.contains('래미안강동팰리스|래미안베라힐즈|래미안솔베뉴|래미안힐스테이트고덕|DMC2차아이파크|DMC센트럴아이파크|DMC에코자이|e편한세상신촌1단지|고덕센트럴IPARK|고덕숲아이파크|마포센트럴아이파크|마포한강아이파크|백련산힐스테이트4차|북한산더샵|불광롯데캐슬|송파와이즈더샵|신촌숲아이파크|연희파크푸르지오|은평스카이뷰자이|이편한세상신촌(1단지)|힐스테이트 강동 리버뷰|힐스테이트녹번|힐스테이트암사|고덕롯데캐슬베네루체', regex=True, na=False)]
df_APT_filtered2 = df_df2[df_df2['BLDG_NM'].str.contains('래미안강동팰리스|래미안베라힐즈|래미안솔베뉴|래미안힐스테이트고덕|DMC2차아이파크|DMC센트럴아이파크|DMC에코자이|e편한세상신촌1단지|고덕센트럴IPARK|고덕숲아이파크|마포센트럴아이파크|마포한강아이파크|백련산힐스테이트4차|북한산더샵|불광롯데캐슬|송파와이즈더샵|신촌숲아이파크|연희파크푸르지오|은평스카이뷰자이|이편한세상신촌(1단지)|힐스테이트 강동 리버뷰|힐스테이트녹번|힐스테이트암사|고덕롯데캐슬베네루체', regex=True, na=False)]
df_APT_filtered3 = df_df3[df_df3['BLDG_NM'].str.contains('래미안강동팰리스|래미안베라힐즈|래미안솔베뉴|래미안힐스테이트고덕|DMC2차아이파크|DMC센트럴아이파크|DMC에코자이|e편한세상신촌1단지|고덕센트럴IPARK|고덕숲아이파크|마포센트럴아이파크|마포한강아이파크|백련산힐스테이트4차|북한산더샵|불광롯데캐슬|송파와이즈더샵|신촌숲아이파크|연희파크푸르지오|은평스카이뷰자이|이편한세상신촌(1단지)|힐스테이트 강동 리버뷰|힐스테이트녹번|힐스테이트암사|고덕롯데캐슬베네루체', regex=True, na=False)]
df_APT_filtered4 = df_df4[df_df4['BLDG_NM'].str.contains('래미안강동팰리스|래미안베라힐즈|래미안솔베뉴|래미안힐스테이트고덕|DMC2차아이파크|DMC센트럴아이파크|DMC에코자이|e편한세상신촌1단지|고덕센트럴IPARK|고덕숲아이파크|마포센트럴아이파크|마포한강아이파크|백련산힐스테이트4차|북한산더샵|불광롯데캐슬|송파와이즈더샵|신촌숲아이파크|연희파크푸르지오|은평스카이뷰자이|이편한세상신촌(1단지)|힐스테이트 강동 리버뷰|힐스테이트녹번|힐스테이트암사|고덕롯데캐슬베네루체', regex=True, na=False)]
df_APT_filtered5 = df_df5[df_df5['BLDG_NM'].str.contains('래미안강동팰리스|래미안베라힐즈|래미안솔베뉴|래미안힐스테이트고덕|DMC2차아이파크|DMC센트럴아이파크|DMC에코자이|e편한세상신촌1단지|고덕센트럴IPARK|고덕숲아이파크|마포센트럴아이파크|마포한강아이파크|백련산힐스테이트4차|북한산더샵|불광롯데캐슬|송파와이즈더샵|신촌숲아이파크|연희파크푸르지오|은평스카이뷰자이|이편한세상신촌(1단지)|힐스테이트 강동 리버뷰|힐스테이트녹번|힐스테이트암사|고덕롯데캐슬베네루체', regex=True, na=False)]
df_APT_filtered6 = df_df6[df_df6['BLDG_NM'].str.contains('래미안강동팰리스|래미안베라힐즈|래미안솔베뉴|래미안힐스테이트고덕|DMC2차아이파크|DMC센트럴아이파크|DMC에코자이|e편한세상신촌1단지|고덕센트럴IPARK|고덕숲아이파크|마포센트럴아이파크|마포한강아이파크|백련산힐스테이트4차|북한산더샵|불광롯데캐슬|송파와이즈더샵|신촌숲아이파크|연희파크푸르지오|은평스카이뷰자이|이편한세상신촌(1단지)|힐스테이트 강동 리버뷰|힐스테이트녹번|힐스테이트암사|고덕롯데캐슬베네루체', regex=True, na=False)]
df_APT_filtered7 = AP4[AP4['BLDG_NM'].str.contains('래미안강동팰리스|래미안베라힐즈|래미안솔베뉴|래미안힐스테이트고덕|DMC2차아이파크|DMC센트럴아이파크|DMC에코자이|e편한세상신촌1단지|고덕센트럴IPARK|고덕숲아이파크|마포센트럴아이파크|마포한강아이파크|백련산힐스테이트4차|북한산더샵|불광롯데캐슬|송파와이즈더샵|신촌숲아이파크|연희파크푸르지오|은평스카이뷰자이|이편한세상신촌(1단지)|힐스테이트 강동 리버뷰|힐스테이트녹번|힐스테이트암사|고덕롯데캐슬베네루체', regex=True, na=False)]
df_APT_filtered3_1 = df_APT_filtered3.replace(to_replace='힐스테이트암사',value='힐스테이트 강동 리버뷰')
df_APT_filtered7_1 = df_APT_filtered7.replace(to_replace='힐스테이트암사',value='힐스테이트 강동 리버뷰')
df_APT_filtered7_2 = df_APT_filtered7_1.replace(to_replace='이편한세상신촌(1단지)',value='e편한세상신촌1단지')
#한번에 볼 수 있게 피벗
pivot_tableA = pd.pivot_table(df_APT_filtered,index=['area_dict','CGG_NM','STDG_NM','BLDG_NM'],columns='RCPT_YR',values='THING_AMT',aggfunc='mean') ##18
pivot_tableB = pd.pivot_table(df_APT_filtered2,index=['area_dict','CGG_NM','STDG_NM','BLDG_NM'],columns='RCPT_YR',values='THING_AMT',aggfunc='mean') ##19
pivot_tableC = pd.pivot_table(df_APT_filtered3_1,index=['area_dict','CGG_NM','STDG_NM','BLDG_NM'],columns='RCPT_YR',values='THING_AMT',aggfunc='mean') ##20
pivot_tableD = pd.pivot_table(df_APT_filtered4,index=['area_dict','CGG_NM','STDG_NM','BLDG_NM'],columns='RCPT_YR',values='THING_AMT',aggfunc='mean') ##21
pivot_tableE = pd.pivot_table(df_APT_filtered5,index=['area_dict','CGG_NM','STDG_NM','BLDG_NM'],columns='RCPT_YR',values='THING_AMT',aggfunc='mean') ##22
pivot_tableF = pd.pivot_table(df_APT_filtered6,index=['area_dict','CGG_NM','STDG_NM','BLDG_NM'],columns='RCPT_YR',values='THING_AMT',aggfunc='mean') ##23
pivot_tableG = pd.pivot_table(df_APT_filtered7_2,index=['area_dict','CGG_NM','STDG_NM','BLDG_NM'],columns='RCPT_YR',values='THING_AMT',aggfunc='mean') ##24
pivot_tableG
#groupby
groupA =df_APT_filtered.groupby(['area_dict','CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean() ##2018
groupB =df_APT_filtered2.groupby(['area_dict','CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean() ##2019
groupC =df_APT_filtered3_1.groupby(['area_dict','CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean() ##2020
groupD =df_APT_filtered4.groupby(['area_dict','CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean() ##2021
groupE =df_APT_filtered5.groupby(['area_dict','CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean() ##2022
groupF =df_APT_filtered6.groupby(['area_dict','CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean() ##2023
groupG =df_APT_filtered7_2.groupby(['area_dict','CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean() ##2024
##브랜드 별 칼럼 피벗테이블 완료
check_df = pd.concat([groupA, groupB, groupC, groupD, groupE, groupF, groupG], axis=1)
check_df.columns = [2018, 2019, 2020, 2021, 2022, 2023, 2024] # 연도별 컬럼 이름 지정
check_df
cd3 = check_df.round(0)
cd3.sort_values(by=['area_dict','CGG_NM','STDG_NM'])
cd3
필터를 안걸었을 때는 이게 값이다. 그럼 필터를 건 값들은?
###9층 이상의 건물들만 확인
df_APT_filtered['FLR'] = df_APT_filtered['FLR'].astype(int)
df_APT_filtered2['FLR'] = df_APT_filtered2['FLR'].astype(int)
df_APT_filtered3['FLR'] = df_APT_filtered3['FLR'].astype(int)
df_APT_filtered4['FLR'] = df_APT_filtered4['FLR'].astype(int)
df_APT_filtered5['FLR'] = df_APT_filtered5['FLR'].astype(int)
df_APT_filtered6['FLR'] = df_APT_filtered6['FLR'].astype(int)
df_APT_filtered7_2['FLR'] = df_APT_filtered7_2['FLR'].astype(int)
##평수 iNT 화
df_APT_filtered['ARCH_YR'] = df_APT_filtered['ARCH_YR'].astype(int)
df_APT_filtered2['ARCH_YR'] = df_APT_filtered2['ARCH_YR'].astype(int)
df_APT_filtered3['ARCH_YR'] = df_APT_filtered3['ARCH_YR'].astype(int)
df_APT_filtered4['ARCH_YR'] = df_APT_filtered4['ARCH_YR'].astype(int)
df_APT_filtered5['ARCH_YR'] = df_APT_filtered5['ARCH_YR'].astype(int)
df_APT_filtered6['ARCH_YR'] = df_APT_filtered6['ARCH_YR'].astype(int)
df_APT_filtered7_2['ARCH_YR'] = df_APT_filtered7_2['ARCH_YR'].astype(int)
##9층 이상
df_APT_filtered_9 = df_APT_filtered[df_APT_filtered['FLR']>=9]
df_APT_filtered2_9 = df_APT_filtered2[df_APT_filtered2['FLR']>=9]
df_APT_filtered3_9 = df_APT_filtered3_1[df_APT_filtered3['FLR']>=9]
df_APT_filtered4_9 = df_APT_filtered4[df_APT_filtered4['FLR']>=9]
df_APT_filtered5_9 = df_APT_filtered5[df_APT_filtered5['FLR']>=9]
df_APT_filtered6_9 = df_APT_filtered6[df_APT_filtered6['FLR']>=9]
##평수 제한
df_APT1 = df_APT_filtered_9[df_APT_filtered_9['ARCH_AREA']>=66]
df_APT2 = df_APT1[df_APT1['ARCH_AREA']<=132] ##18
df_APT3 = df_APT_filtered2_9[df_APT_filtered2_9['ARCH_AREA']>=66]
df_APT4 = df_APT3[df_APT3['ARCH_AREA']<=132]
df_APT5 = df_APT_filtered3_9[df_APT_filtered3_9['ARCH_AREA']>=66]
df_APT6 = df_APT5[df_APT5['ARCH_AREA']<=132]
df_APT7 = df_APT_filtered4_9[df_APT_filtered4_9['ARCH_AREA']>=66]
df_APT8 = df_APT7[df_APT7['ARCH_AREA']<=132]
df_APT9 = df_APT_filtered5_9[df_APT_filtered5_9['ARCH_AREA']>=66]
df_APT10 = df_APT9[df_APT9['ARCH_AREA']<=132]
df_APT11 = df_APT_filtered6_9[df_APT_filtered6_9['ARCH_AREA']>=66]
df_APT12 = df_APT11[df_APT11['ARCH_AREA']<=132]
df_APT13 = df_APT_filtered7_2[df_APT_filtered7_2['ARCH_AREA']>=66]
df_APT14 = df_APT13[df_APT13['ARCH_AREA']<=132]
APTc1 =df_APT2.groupby(['area_dict','CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean() ##2018
APTc2 =df_APT4.groupby(['area_dict','CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean() ##2019
APTc3 =df_APT6.groupby(['area_dict','CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean() ##2020
APTc4 =df_APT8.groupby(['area_dict','CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean() ##2021
APTc5 =df_APT10.groupby(['area_dict','CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean() ##2022
APTc6 =df_APT12.groupby(['area_dict','CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean() ##2023
APTc7 =cond3.groupby(['area_dict','CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean() ##2024
APTc9 =df_APT2.groupby(['area_dict','CGG_NM'])['THING_AMT'].mean() ##2018
APTc10 =df_APT4.groupby(['area_dict','CGG_NM'])['THING_AMT'].mean() ##2019
APTc11 =df_APT6.groupby(['area_dict','CGG_NM'])['THING_AMT'].mean() ##2020
APTc12 =df_APT8.groupby(['area_dict','CGG_NM'])['THING_AMT'].mean() ##2021
APTc13 =df_APT10.groupby(['area_dict','CGG_NM'])['THING_AMT'].mean() ##2022
APTc14 =df_APT12.groupby(['area_dict','CGG_NM'])['THING_AMT'].mean() ##2023
APTc15 =cond3.groupby(['area_dict','CGG_NM'])['THING_AMT'].mean() ##2024
ck123 = pd.concat([APTc1,APTc2,APTc3,APTc4,APTc5,APTc6,APTc7],axis=1,ignore_index=False)
ck123.columns = [2018, 2019, 2020, 2021, 2022, 2023, 2024]
ck456 = pd.concat([APTc9,APTc10,APTc11,APTc12,APTc13,APTc14,APTc15],axis=1,ignore_index=False)
ck456.columns = [2018, 2019, 2020, 2021, 2022, 2023, 2024]
cd = cd.sort_values(by=['area_dict'])
cd2 = cd2.sort_values(by=['area_dict','CGG_NM'])
cd3 = cd3.sort_values(by=['area_dict','CGG_NM','STDG_NM'])
cd4 = ck123.sort_values(by=['area_dict','CGG_NM','STDG_NM'])필터 건 값 ck123은 이렇게 나온다.


일단은 이렇게 나온다. 굉장히 좀 복잡하게 나오긴 했다. 그럼 혹시 전체 데이터 중에서 이상치는 없을까...?
일단 도메인 지식에 따르면 부동산 실제 거래가는 정규분포로 만들기가 어렵다고 한다. 그 이유는, 오른쪽 끝으로 길게 늘어지는 분포로 이어질 뿐만이 아니라 실제로도 "주택 매매가격 분포를 통한 지역별, 가격대별 변동성 분석”(2021, 주택금융연구원)에서도 사장상황에 따라서 변동성이 크다고 지적했다.(호황기, 불황기마다 달라진다고)
일단은 그래도 모르니 iqr 로 시도는 해봤다.
##이상치 iqr
partment4 = bf4.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].sum()
apartment5 = bf5.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].sum()
apartment6 = bf6.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].sum()
apartment7 = AP1.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].sum()
apartment4.mean(),apartment5.mean(),apartment6.mean(),apartment7.mean()
jk1 = bf4[bf4['DCLR_SE'] == '직거래']
jk2 = bf5[bf5['DCLR_SE'] == '직거래']
jk3 = bf6[bf6['DCLR_SE'] == '직거래']
jk4 = AP1[AP1['DCLR_SE'] == '직거래']
JJK1 = jk1.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].sum()
JJK2 = jk2.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].sum()
JJK3 = jk3.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].sum()
JJK4 = jk4.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].sum()
JJK1.mean(),JJK2.mean(),JJK3.mean(),JJK4.mean()
JG1 = bf4[(bf4['DCLR_SE'].isna() | (bf4['DCLR_SE'] == '중개거래'))]
JG2 = bf5[(bf5['DCLR_SE'].isna() | (bf5['DCLR_SE'] == '중개거래'))]
JG3 = bf6[(bf6['DCLR_SE'].isna() | (bf6['DCLR_SE'] == '중개거래'))]
JG4 = AP1[(AP1['DCLR_SE'].isna() | (bf6['DCLR_SE'] == '중개거래'))]
jg1 = JG1.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].sum()
jg2 = JG2.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].sum()
jg3 = JG3.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].sum()
jg4 = JG4.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].sum()
jg1.mean(),jg2.mean(),jg3.mean(),jg4.mean()
mean_all = AP1['THING_AMT'].mean() ##아파트만
mean_jg4 = JG4['THING_AMT'].mean() ##중고거래 + 난값
mean_jk4 = jk4['THING_AMT'].mean() ##직거라면
jk_ratio = mean_jk4 / mean_jg4
jggr_ratio = mean_jg4 / mean_all
jgr_ratio = mean_jk4 / mean_all
mean_jg4,mean_jk4,jk_ratio
int(mean_all),int(mean_jg4),int(mean_jk4),int,jk_ratio,jggr_ratio,jgr_ratio
print(f"중개거래 평균: {mean_jg4:.2f}")
print(f"직거래 평균: {mean_jk4:.2f}")
print(f"전체 평균: {mean_all:.2f}")
print(f"직거래/중개거래 비율: {jk_ratio:.2%}")
print(f"중개거래/전체평균 비율: {jggr_ratio:.2%}")
print(f"직거래/전체평균 비율: {jgr_ratio:.2%}")
esang1 = df7[['THING_AMT']] ##모든필터X 일반 데이터
q3 = esang1['THING_AMT'].quantile(0.75)
q1 = esang1['THING_AMT'].quantile(0.25)
iqr = q3 - q1
q3, q1, iqr
outline = esang1[(esang1['THING_AMT'] < q1 - 1.5 * iqr) | (jk4['THING_AMT'] > q3 + 1.5 * iqr)]
Q1 = jk4['THING_AMT'].quantile(0.25) # 1사분위 ##직거래만 한번 필터링
Q3 = jk4['THING_AMT'].quantile(0.75) # 3사분위
IQR = Q3 - Q1
outline2 = jk4[(jk4['THING_AMT'] < Q1 - 1.5 * IQR) | (jk4['THING_AMT'] > Q3 + 1.5 * IQR)]
esang2 = AP1[['THING_AMT']] ##2024년 아파트만 필터링
q3 = esang2['THING_AMT'].quantile(0.75)
q1 = esang2['THING_AMT'].quantile(0.25)
iqr = q3 - q1
q3, q1, iqr
outline3 = esang2[(esang2['THING_AMT'] < Q1 - 1.5 * IQR) | (esang2['THING_AMT'] > Q3 + 1.5 * IQR)]
esang1['이상치여부'] = esang1.apply(is_outlier, axis = 1) # axis = 1 지정 필수
jk4['이상치여부'] = jk4.apply(is_outlier, axis = 1) # axis = 1 지정 필수
esang2['이상치여부'] = esang2.apply(is_outlier, axis = 1) # axis = 1 지정 필수
esang1['이상치여부']
dfdfdf = pd.concat([df7,esang1['이상치여부']],axis=1)
bffffff = jk4[jk4['이상치여부'] == '이상치']
bffffff
bdddd = pd.concat([AP1,esang2['이상치여부']],axis=1)
CKCK1 = dfdfdf[dfdfdf['이상치여부'] == '이상치']
CKCK2 = jk4[jk4['이상치여부'] == '이상치']
CKCK3 = bdddd[bdddd['이상치여부'] == '이상치']
CKCK11 = CKCK1.tail(8)
CKCK12 = CKCK2.head(8)
CKCK13 = CKCK3.tail(8)
CKCK14 = CKCK11[['CGG_NM','STDG_NM','BLDG_NM','CTRT_DAY','THING_AMT','ARCH_AREA','DCLR_SE','이상치여부']]
CKCK15 = CKCK12[['CGG_NM','STDG_NM','BLDG_NM','CTRT_DAY','THING_AMT','ARCH_AREA','DCLR_SE','이상치여부']]
CKCK16 = CKCK13[['CGG_NM','STDG_NM','BLDG_NM','CTRT_DAY','THING_AMT','ARCH_AREA','DCLR_SE','이상치여부']]
##8361 rows × 24 columns결론적으로 의미가 있었냐고 하면 전혀 아니였다. 정말로 이상치인 값도 있었지만, 정상적인 값임에도 불구하고 이걸 이상치로 판단하는 경우가 있어서 제외해야했다. 그리고 생각보다 정규분포를 그렇게 따르지도 않았다. 그래서 이 분석은 거의 의미가 없었다.
##레미안
df_ra = aaap1.loc[aaap1['BLDG_NM'].str.contains('래미안')]
df_ra2 = aaap2.loc[aaap2['BLDG_NM'].str.contains('래미안')]
df_ra3 = aaap3.loc[aaap3['BLDG_NM'].str.contains('래미안')]
df_ra4 = aaap4.loc[aaap4['BLDG_NM'].str.contains('래미안')]
df_ra5 = aaap5.loc[aaap5['BLDG_NM'].str.contains('래미안')]
df_ra6 = aaap6.loc[aaap6['BLDG_NM'].str.contains('래미안')]
df_ra7 = AP4.loc[AP4['BLDG_NM'].str.contains('래미안')]
groupraA =df_ra.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean()
groupraB = df_ra2.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean()
groupraC = df_ra3.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean()
groupraD = df_ra4.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean()
groupraE = df_ra5.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean()
groupraF = df_ra6.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean()
groupraG = df_ra7.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean()
check_df7 = pd.concat([groupraA, groupraB, groupraC, groupraD, groupraE, groupraF, groupraG], axis=1)
check_df7.columns = [2018, 2019, 2020, 2021, 2022, 2023, 2024] # 연도별 컬럼 이름 지정
check_df7
RM = check_df7.mean()
##힐스테이트
df_hi = aaap1.loc[aaap1['BLDG_NM'].str.contains('힐스테이트')]
df_hi2 = aaap2.loc[aaap2['BLDG_NM'].str.contains('힐스테이트')]
df_hi3 = aaap3.loc[aaap3['BLDG_NM'].str.contains('힐스테이트')]
df_hi4 = aaap4.loc[aaap4['BLDG_NM'].str.contains('힐스테이트')]
df_hi5 = aaap5.loc[aaap5['BLDG_NM'].str.contains('힐스테이트')]
df_hi6 = aaap6.loc[aaap6['BLDG_NM'].str.contains('힐스테이트')]
df_hi7 = AP4.loc[AP4['BLDG_NM'].str.contains('힐스테이트')]
grouphiA =df_hi.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean()
grouphiB = df_hi2.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean()
grouphiC = df_hi3.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean()
grouphiD = df_hi4.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean()
grouphiE = df_hi5.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean()
grouphiF = df_hi6.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean()
grouphiG = df_hi7.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean()
check_df8 = pd.concat([grouphiA, grouphiB, grouphiC, grouphiD, grouphiE, grouphiF, grouphiG], axis=1)
check_df8.columns = [2018, 2019, 2020, 2021, 2022, 2023, 2024] # 연도별 컬럼 이름 지정
check_df8
HS = check_df8.mean()
##디에이치
df_dh = aaap1.loc[aaap1['BLDG_NM'].str.contains('디에이치')]
df_dh2 = aaap2.loc[aaap2['BLDG_NM'].str.contains('디에이치')]
df_dh3 = aaap3.loc[aaap3['BLDG_NM'].str.contains('디에이치')]
df_dh4 = aaap4.loc[aaap4['BLDG_NM'].str.contains('디에이치')]
df_dh5 = aaap5.loc[aaap5['BLDG_NM'].str.contains('디에이치')]
df_dh6 = aaap6.loc[aaap6['BLDG_NM'].str.contains('디에이치')]
df_dh7 = AP4.loc[AP4['BLDG_NM'].str.contains('디에이치')]
groupdhA =df_dh.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean()
groupdhB = df_dh2.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean()
groupdhC = df_dh3.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean()
groupdhD = df_dh4.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean()
groupdhE = df_dh5.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean()
groupdhF = df_dh6.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean()
groupdhG = df_dh7.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean()
check_df9 = pd.concat([groupdhA, groupdhB, groupdhC, groupdhD, groupdhE, groupdhF, groupdhG], axis=1)
check_df9.columns = [2018, 2019, 2020, 2021, 2022, 2023, 2024] # 연도별 컬럼 이름 지정
check_df9
DH = check_df9.mean()
##푸르지오
df_pr = aaap1.loc[aaap1['BLDG_NM'].str.contains('푸르지오')]
df_pr2 = aaap2.loc[aaap2['BLDG_NM'].str.contains('푸르지오')]
df_pr3 = aaap3.loc[aaap3['BLDG_NM'].str.contains('푸르지오')]
df_pr4 = aaap4.loc[aaap4['BLDG_NM'].str.contains('푸르지오')]
df_pr5 = aaap5.loc[aaap5['BLDG_NM'].str.contains('푸르지오')]
df_pr6 = aaap6.loc[aaap6['BLDG_NM'].str.contains('푸르지오')]
df_pr7 = AP4.loc[AP4['BLDG_NM'].str.contains('푸르지오')]
groupprA =df_pr.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean()
groupprB = df_pr2.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean()
groupprC = df_pr3.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean()
groupprD = df_pr4.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean()
groupprE = df_pr5.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean()
groupprF = df_pr6.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean()
groupprG = df_pr7.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean()
check_df10 = pd.concat([groupprA, groupprB, groupprC, groupprD, groupprE, groupprF, groupprG], axis=1)
check_df10.columns = [2018, 2019, 2020, 2021, 2022, 2023, 2024] # 연도별 컬럼 이름 지정
check_df10
PR = check_df10.mean()
##자이
df_xi = aaap1.loc[aaap1['BLDG_NM'].str.contains('자이')]
df_xi2 = aaap2.loc[aaap2['BLDG_NM'].str.contains('자이')]
df_xi3 = aaap3.loc[aaap3['BLDG_NM'].str.contains('자이')]
df_xi4 = aaap4.loc[aaap4['BLDG_NM'].str.contains('자이')]
df_xi5 = aaap5.loc[aaap5['BLDG_NM'].str.contains('자이')]
df_xi6 = aaap6.loc[aaap6['BLDG_NM'].str.contains('자이')]
df_xi7 = AP4.loc[AP4['BLDG_NM'].str.contains('자이')]
groupxiA =df_xi.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean()
groupxiB = df_xi2.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean()
groupxiC = df_xi3.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean()
groupxiD = df_xi4.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean()
groupxiE = df_xi5.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean()
groupxiF = df_xi6.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean()
groupxiG = df_xi7.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean()
check_df11 = pd.concat([groupxiA, groupxiB, groupxiC, groupxiD, groupxiE, groupxiF, groupxiG], axis=1)
check_df11.columns = [2018, 2019, 2020, 2021, 2022, 2023, 2024] # 연도별 컬럼 이름 지정
check_df11
XI = check_df11.mean()
##이편한세상
df_ep = aaap1.loc[aaap1['BLDG_NM'].str.contains('e|편한')]
df_ep2 = aaap2.loc[aaap2['BLDG_NM'].str.contains('e|편한')]
df_ep3 = aaap3.loc[aaap3['BLDG_NM'].str.contains('e|편한')]
df_ep4 = aaap4.loc[aaap4['BLDG_NM'].str.contains('e|편한')]
df_ep5 = aaap5.loc[aaap5['BLDG_NM'].str.contains('e|편한')]
df_ep6 = aaap6.loc[aaap6['BLDG_NM'].str.contains('e|편한')]
df_ep7 = AP4.loc[AP4['BLDG_NM'].str.contains('편한')]
groupepA =df_ep.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean()
groupepB = df_ep2.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean()
groupepC = df_ep3.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean()
groupepD = df_ep4.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean()
groupepE = df_ep5.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean()
groupepF = df_ep6.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean()
groupepG = df_ep7.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean()
check_df12 = pd.concat([groupepA, groupepB, groupepC, groupepD, groupepE, groupepF, groupepG], axis=1)
check_df12.columns = [2018, 2019, 2020, 2021, 2022, 2023, 2024] # 연도별 컬럼 이름 지정
check_df12
EP = check_df12.mean()
##아크로
df_acr = aaap1.loc[aaap1['BLDG_NM'].str.contains('아크')]
df_acr2 = aaap2.loc[aaap2['BLDG_NM'].str.contains('아크')]
df_acr3 = aaap3.loc[aaap3['BLDG_NM'].str.contains('아크')]
df_acr4 = aaap4.loc[aaap4['BLDG_NM'].str.contains('아크')]
df_acr5 = aaap5.loc[aaap5['BLDG_NM'].str.contains('아크')]
df_acr6 = aaap6.loc[aaap6['BLDG_NM'].str.contains('아크')]
df_acr7 = AP4.loc[AP4['BLDG_NM'].str.contains('아크')]
groupacrA =df_acr.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean()
groupacrB = df_acr2.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean()
groupacrC = df_acr3.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean()
groupacrD = df_acr4.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean()
groupacrE = df_acr5.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean()
groupacrF = df_acr6.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean()
groupacrG = df_acr7.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean()
check_df13 = pd.concat([groupacrA, groupacrB, groupacrC, groupacrD, groupacrE, groupacrF, groupacrG], axis=1)
check_df13.columns = [2018, 2019, 2020, 2021, 2022, 2023, 2024] # 연도별 컬럼 이름 지정
check_df13
ACR = check_df13.mean()
##더샵
df_ts = aaap1.loc[aaap1['BLDG_NM'].str.contains('더샵')]
df_ts2 = aaap2.loc[aaap2['BLDG_NM'].str.contains('더샵')]
df_ts3 = aaap3.loc[aaap3['BLDG_NM'].str.contains('더샵')]
df_ts4 = aaap4.loc[aaap4['BLDG_NM'].str.contains('더샵')]
df_ts5 = aaap5.loc[aaap5['BLDG_NM'].str.contains('더샵')]
df_ts6 = aaap6.loc[aaap6['BLDG_NM'].str.contains('더샵')]
df_ts7 = AP4.loc[AP4['BLDG_NM'].str.contains('더샵')]
grouptsA =df_ts.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean()
grouptsB = df_ts2.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean()
grouptsC = df_ts3.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean()
grouptsD = df_ts4.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean()
grouptsE = df_ts5.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean()
grouptsF = df_ts6.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean()
grouptsG = df_ts7.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean()
check_df14 = pd.concat([grouptsA, grouptsB, grouptsC, grouptsD, grouptsE, grouptsF, grouptsG], axis=1)
check_df14.columns = [2018, 2019, 2020, 2021, 2022, 2023, 2024] # 연도별 컬럼 이름 지정
check_df14
TS = check_df14.mean()
##에스케이
df_sk = aaap1.loc[aaap1['BLDG_NM'].str.contains('SK|에스케이')]
df_sk2 = aaap2.loc[aaap2['BLDG_NM'].str.contains('SK|에스케이')]
df_sk3 = aaap3.loc[aaap3['BLDG_NM'].str.contains('SK|에스케이')]
df_sk4 = aaap4.loc[aaap4['BLDG_NM'].str.contains('SK|에스케이')]
df_sk5 = aaap5.loc[aaap5['BLDG_NM'].str.contains('SK|에스케이')]
df_sk6 = aaap6.loc[aaap6['BLDG_NM'].str.contains('SK|에스케이')]
df_sk7 = AP4.loc[AP4['BLDG_NM'].str.contains('SK|에스케이')]
groupskA =df_sk.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean()
groupskB = df_sk2.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean()
groupskC = df_sk3.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean()
groupskD = df_sk4.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean()
groupskE = df_sk5.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean()
groupskF = df_sk6.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean()
groupskG = df_sk7.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean()
check_df15 = pd.concat([groupskA, groupskB, groupskC, groupskD, groupskE, groupskF, groupskG], axis=1)
check_df15.columns = [2018, 2019, 2020, 2021, 2022, 2023, 2024] # 연도별 컬럼 이름 지정
check_df15
SK = check_df15.mean()
##아이파크
df_pk = aaap1.loc[aaap1['BLDG_NM'].str.contains('아이파크|PARK')]
df_pk2 = aaap2.loc[aaap2['BLDG_NM'].str.contains('아이파크|PARK')]
df_pk3 = aaap3.loc[aaap3['BLDG_NM'].str.contains('아이파크|PARK')]
df_pk4 = aaap4.loc[aaap4['BLDG_NM'].str.contains('아이파크|PARK')]
df_pk5 = aaap5.loc[aaap5['BLDG_NM'].str.contains('아이파크|PARK')]
df_pk6 = aaap6.loc[aaap6['BLDG_NM'].str.contains('아이파크|PARK')]
df_pk7 = AP4.loc[AP4['BLDG_NM'].str.contains('아이파크|PARK')]
grouppkA =df_pk.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean()
grouppkB = df_pk2.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean()
grouppkC = df_pk3.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean()
grouppkD = df_pk4.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean()
grouppkE = df_pk5.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean()
grouppkF = df_pk6.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean()
grouppkG = df_pk7.groupby(['CGG_NM','STDG_NM','BLDG_NM'])['THING_AMT'].mean()
check_df16 = pd.concat([grouppkA, grouppkB, grouppkC, grouppkD, grouppkE, grouppkF, grouppkG], axis=1)
check_df16.columns = [2018, 2019, 2020, 2021, 2022, 2023, 2024] # 연도별 컬럼 이름 지정
check_df16
PK = check_df16.mean()
##브랜드 표
brand = pd.concat([RM,HS,DH,PR,XI,EP,ACR,TS,SK,PK],axis=1)
brand.columns = ["RAEMIAN","HILLSTATE","DH","Prugio","Xi","E-Sesang","ACRO","THE SHARP","SK","IPARK"]
brand.transpose()
brand.astype('int')
brand1 = pd.concat([RM,HS,DH,PR,XI],axis=1)
brand1.columns = ["RAEMIAN","HILLSTATE","DH","Prugio","Xi"]
brand2 = pd.concat([EP,ACR,TS,SK,PK],axis=1)
brand2.columns = ["E-Sesang","ACRO","THE SHARP","SK","IPARK"]
brand1
brand.reset_index(drop=False)
brand1.reset_index(drop=False)
brand2.reset_index(drop=False)
brand
근데 결론적으로 보면.. 그렇게 많이 오른거 내린거 차이가 크지 안. 그나마 아크로가 가장 높지만... 15억 이하니까 힐스테이트, 푸르지오, 이편한세상, 아이파크, SK 정도로 추려졌다.
훔... 그치만 이걸로는 부족해서 좀 더 이제 다른 PPT 만든걸로 좀 더 검토했다.
이제 이상치랑 결측치는 다음과 같이 정리했다.


이번에 이상치 데이터로 취소 데이터가 굉장히 많이 싸웠는데....
사실, 취소 데이터가 무조건 이상치는 아니지만, 여러매물이 등록되면 헷갈릴 수 있기도 하고, 실거래가를 분석하는 거니까 이상치로 정의해서 뺐다. IQR 이랑 Z-score 을 못쓰기 때문이다.
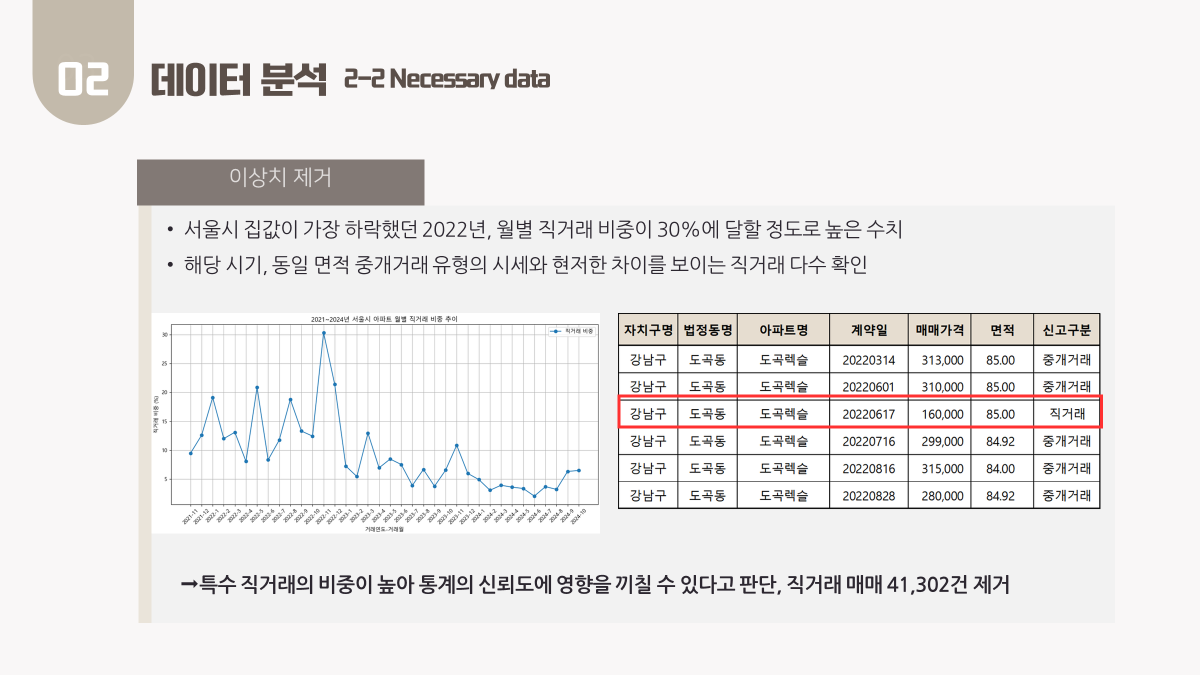
직거래는 따른 매물보다 빠르니까 패스! 이건 차라리 없애는 게 맞기도 했다. 사실 공유 안한 게... 직거래는 일단 공인중개사인 우리를 거치지 않았다는게 이유니까 당연히 뺴야한다고 본다... 이건 너무 당연했다...


이부분에 대해서 설명하는게 넘 어려웠다.
이게 사실은 튜터님께서 내가 구한 표도 시세를 분석할 수 있는 지표다! 라고 했는데, 다들 못쓸..거 같다고 하셔서 ㅜㅜ 넘속상하지만 어쩌겠어요. 빼야지. 그래서 그걸 대체해서 보는게 자치구별로 보는거다! 라고 설명했다. 사실 아파트를 설명을 못하면 동이나 구를 봐야하니까.

이번에 그래서 뭐... 랜덤 포레스트로 조원분께서 넣어서 만들어주셨다.
근데 솔직히 발표에 들어갔다면 좋았을 것. 음... 그래서 각 칼럼이 뭘 뜻하는지(혼자서 보려니까 감당이 안됨), 그래서 요인별 상관 관계 분석으로 예측모델을 어떻게 쓰셨는지 궁금했는데 발표가 쪽박해서 듣지는 못했다.
예상을 한다면, 2025년 가상 예측 모델을 만들어서 요인별 상관 관계를 만들고 거기에 따른 걸 만든다! 라고 생각된다. 그래서 총 이것저것 고려해본 결과... 발표 당일 날에야 정할 수 있었다. 평수도 제대로 못본게 아쉽다. 같이 좀 더 피드백 해줬으면 좋겠는대 생각보다 시간이안났다.

진짜 이것저것 새벽에 발표하기 전에 고덕숲 아이파크에 대해서 계속 찾아봤던거 같다. 왜 좋고, 주민들은 뭐고... 85 m² 관련해서도 고치고 싶었고. 사실 고백하자면 발표 후에 실수했대서 겁나 좀 울었어요. 진짜로 속상해서. 완벽주의적인 면이 있고 되게 고치려고 하는데도 힘들었거든요.
이번에 조원분들께서 다독여주셔서 조금 괜찮았습니다. 그래도 제 완벽주의가 아니라, 조금 부족하더라도 조원분들을 따라 가는 걸로 이번에 많이 노력했어요. 가끔.. 의견차도 있었고, 말도 크게 나왔지만.... 그래도 힘냈어요.
그래서 부랴부랴 발표 내고서 좀 울었다. 잘 안된 거 같아서... 그래도 힘내서 했다.
이번에 좀 아쉬웠던 점은 좀 더 속도를 내서 했어야 했는데 그게 잘 안되기도 했다. 그리고 팀원들끼리 어디서 뭘 하는지 공유를 했으면 좋겠다는 생각이 들었다. 개인적인 KPT 소감
유지할 것 KEEP
- 모든 팀원이 적극적으로 협업하려는 태도를 보여 업무가 수월하게 진행되었다.
- 서로 아는 지식을 잘 공유해 주어 팀 전체의 지식이 쌓이는 것을 느낄 수 있었다.
- 발표 준비 과정에서 논리적 결함을 잘 발견해 주었고, 활발한 피드백 덕분에 발표에 많은 도움이 되었다.
개선할 점
- 팀원 간의 업무 분담을 보다 명확히 정하면 더 효율적일 것 같다.
- 업무 진행 상황을 서로 더 적극적으로 공유하면 좋을 것 같다.
- 빠듯한 일정으로 인해 프로젝트 진행이 어려웠고, 다들 힘들어하는 모습이 보여 서로를 배려하는 대화가 더 필요했다고 생각된다.
- 발표를 준비하면서 PPT 작업에 대해 논의할 시간이 부족해 사전에 시간을 확보하면 더 좋을 것 같다.
개선할 점
- 분석에 들어가기 전에 먼저 가설을 세우는 과정이 필요하다고 느꼈다.
- 팀 노션이나 프로젝트 노션을 활용해 데일리 스크럼 시간을 갖는다면 업무 분담에 더 도움이 될 것 같다.
'𝐓𝐈𝐋 (𝐅𝐨𝐫 𝐂𝐚𝐦𝐩) > 𝐂𝐎𝐃𝐈𝐍𝐆 (𝐒𝐐𝐋, 𝐏𝐘𝐓𝐇𝐎𝐍)' 카테고리의 다른 글
| [𝟐𝟓.𝟎𝟒.𝟎𝟏] 𝐓𝐈𝐋 𝐍𝐎𝐓𝐄 𝟐𝟒 (0) | 2025.04.01 |
|---|---|
| [𝟐𝟓.𝟎𝟑.𝟑𝟏] 𝐓𝐈𝐋 𝐍𝐎𝐓𝐄 𝟐𝟑 (1) | 2025.03.31 |
| [𝟐𝟓.𝟎𝟑.𝟏𝟗] 𝐓𝐈𝐋 𝐍𝐎𝐓𝐄 𝟐𝟏 (0) | 2025.03.19 |
| [𝟐𝟓.𝟎𝟑.𝟏𝟖] 𝐓𝐈𝐋 𝐍𝐎𝐓𝐄 𝟐𝟎 (0) | 2025.03.18 |
| [𝟐𝟓.𝟎𝟑.𝟏𝟒] 𝐓𝐈𝐋 𝐍𝐎𝐓𝐄 𝟏𝟗 (0) | 2025.03.17 |