

0. 개요
오늘 '엑셀보다 쉬운 SQL 5주차'강의를 모두 듣고 그 일부 내용을 정리해보려 한다.
1. WHERE 절로 'NULL (값 없음, 데이터 없음)' 제거 하기
지금 배우는 MY SQL 에 사용할 수 없는 데이터가 존재하거나 값이 없는 경우에는 데이터 출력에 문제가 발생할 수 있다. 일반적으로 NULL 이 대표적이며 NULL 외의 다른 값으로 치환하거나, 없는 값을 제외하여 계산을 할 수도 있다. 일단 현재 들은 강의에서는 WHERE 절을 활용하거나 Coalesce를 사용하여 이를 치환한다.
(1) WHERE -- is not NULL 사용하여 값 제거하기
SELECT 칼럼 1, 칼럼 2
FROM data_table
Where 칼럼n(Null 이 들어간 원하는 칼럼) is not NULL해석하자면 data_table 에서 칼럼1과 2를 가져오는 대신 'NULL' 이 아닌 값을 불러오세요. 라는 의미를 담고 있다.
물론 반대로 WHERE -- is NULL 을 사용해서 공간 값을 불러올 수 있다.
SELECT 칼럼 1, 칼럼 2
FROM data_table
WHERE 칼럼n(NULL 이 들어간 칼럼) IS NULL반대로 IS NULL을 사용하면 공란 값만 출력하여 이를 내보낸다.
SELECT f.customer_id,
f.restaurant_name,
c.age,
c.gender
FROM food_orders f inner join customers c on f.customer_id=c.customer_id이렇게 사용하면, age에 있는 비어있는 값은 제외하고 나머지 값은 그대로 출력된다.

아마 데이터 표를 보자하니 NULL 은 안나오긴 하지만, 일단은 NULL 값은 제외시키고 해당 정수의 값만 출력되기 나왔다.
(2) Coalesce & INFULL&NVL 함수 사용
Coalesce 함수는 '앞서 주어진 칼럼들 중'에서 'NULL'이 아닌 경우의 값을 리턴하라는 의미를 가진 함수이다. NVL 혹은 INFULL 함수도 사용하지만 Coalesce 함수는 좀 더 여러 개의 칼럼에서 값을 반환 할 때, 사용할 수 있는 모양이다.
SELECT COALESCE(칼럼명, "대체할 값")
FROM TABLESELECT f.restaurant_name,f.customer_id,c.age,COALESCE(c.age,10) "NULL 제거",c.gender
FROM food_orders f LEFT JOIN customers c ON f.customer_id=c.customer_id
WHERE c.age is NULL
ORDER BY age ASC이런 경우에는 customer 테이블에 있는 나이(age)란의 값이 원래의 값 대신 10으로 치환되어 있는 것을 확인 할 수 있다. 아마 이 식으로는 안보여서 조금 다른 식으로 변형해서 사용했다.

따로 'NULL 제거'라는 칸 항목이 생겼고, 존재할 수 없는 값들 중 나이(Age)란의 숫자를 10으로 치환한 것을 확인할 수 있다. 만약에 WHERE name IS NOT NULL 이라고 썼다면, NULL값이 없는 모든 데이터가 출력한다.
INFULL 도 Coalesce 와 동일해서 일단 양식만 어떻게든 공부하려고 따로 서식을 가져왔다.
INFULL 함수 형식
SELECT INFULL(칼럼명, "NULL을 대체할 값")
FROM Data_tableAGE 값 중에서 NULL 이 존재하는 경우 동일.
SELECT INFULL(AGE, "없음")
FROM customers근데 해당 함수는 입력이 안되는지 아쉽게도 스크립트에는 적용이 안됐다. 뭔가 잘못쓴걸까? 그래도 혹시 남겨는 두지만 이러한 INFULL 함수에 대한 경로가 없다고 뜬다. 비슷하게 NVL도 그렇게 나오니까 일단은 적용은 된다고 알아만 두면 될거같다.

2. 조회한 값이 상식적이지 않은 경우
- 값이 너무 미래의 값이거나 과거의 값일때
- 너무 어리거나 너무 고령의 나이의 주문 등(1살의 주문건 등)
이러한 경우에는 '조건문'을 활용해서 필터링을 할 수 있다. 앞서 배웠던 IF 와 CASE WHEN을 통해 해당 조건을 완화시켜줄 수 있었다. 해당 조건 구절에 대해서는 아래 TIL에 정리해뒀고, 나도 이걸 참고해서 자주 보는 편이다.
https://bom-rosy.tistory.com/14
[𝟐𝟓.𝟎𝟐.𝟏𝟖] 𝐓𝐈𝐋 𝐍𝐎𝐓𝐄 𝟑
0. 개요오늘은 SQL 에 대해서 배운 것들에 대해서 정리한다.1. REPLACE, SUBSTRING, CONCAT가공문뜻예제REPLACE어떠한 값을 다른 값으로 변환합니다.REPLACE(바꿀 칼럼, 현재 값, 바꿀 값)SELECT ribbon_name "리본
bom-rosy.tistory.com

이렇게 너무 값이 과거일때, 조금 나만의 방식으로 이걸 2000년대 까지로 다시 끊어보려고 한다. 일단은 아직 date 함수에는 익숙하지 않아서, 2000년대 이하의 년들에 한해서 '2000-01-01'로 출력하는 방식으로 바꿔봤다.
SELECT order_id,
CASE WHEN date<2000 then '2000-01-01'
ELSE Date END " 바뀐 날짜"
FROM payments
일단은 나름대로 할 수 있는 선에서 정리해봤다. 오늘 배운 내용 중에는 'DATE' 함수도 있어서 이게 좀 골치 아프지만 '문자열'로 치환할 수 있는 것 중에서는 최대한 선에서 바꿔봤다.
3. SQL 로 피벗 테이블(Pivot Table) 만들기
Pivot Table 의 정의
: 2개 이상의 기준으로 데이터를 집계할 때, 보기 쉽게 배열해 보여주는 표를 말한다. 집계기준, 구분칼럼,데이터 순으로 해당 테이블이 보여지게 되며 SQL을 통해 집계기준과 구분칼럼을 선정할 수 있다.
오늘 배웠던 것 중에서 문장의 흐름을 따라가기 위해서 직접 코드를 하나하나씩 다시 설계해보는 시간을 가졌다.
[문제] 음식점별, 시간별 주문건수 집계하기
[1] 순서에 맞춰서 SQL 코드 짜기
- 필요한 테이블 : food_orders / payments
- 합집합 부분인 : order_id 에서 가져온다.
- 가져와야 할 칼럼 : 식당 이름, 시간, 주문 건수
- 조건식 : 15~20시 사이에 있는 주문건수로 제한함
SELECT f.restaurant_name,
FROM food_orders f INNER JOIN payments p ON f.order_id=p.order_id
시간이 굉장히 번잡스러우므로, 앞에서 11시 / 14시 로 해당하는 시각들만 값을 가져와야한다. 즉, Substring(Substr) 함수도 요구하는 셈이다.
SELECT f.restaurant_name,
SUBSTR(p.time,1,2) hh,
COUNT(1) order_count
FROM food_orders f INNER JOIN payments p ON f.order_id=p.order_id
WHERE SUBSTR(p.time,1,2) BETWEEN 15 AND 20
GROUP BY 1,2count(1) order_count 로 명명한 이유는 각각의 모든 주문을 세야하기 때문이다. 그래서 해당 함수를 출력하면 다음과 같이 출력된다.

[2] 피벗 테이블로 도식화 시키기
이제는 각 칼럼들을 어디에 무엇을 둘 지에 대해서 해야한다.
- 식당명
- 각 주문별로 시간을 한꺼번에 모으기 (15시면 15시끼리, 16시면 16시끼리)
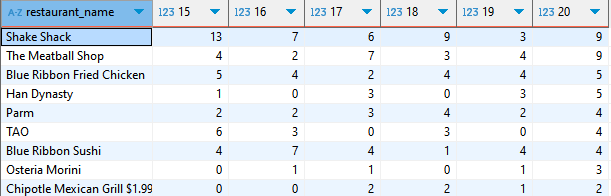
이걸 어떻게 해야 만들수 있을까 고민했다. 일단 substr(--)의 내용을 다시 hh 로 전환해서 다시 표로 치환하면 다음과 같았다. 일단은 그룹별은 식당이름 순으로 내림차순.
SELECT restaurant_name,
MAX(IF(hh='15',order_count,0)) "15",
MAX(IF(hh='16',order_count,0)) "16",
MAX(IF(hh='17',order_count,0)) "17",
MAX(IF(hh='18',order_count,0)) "18",
MAX(IF(hh='19',order_count,0)) "19",
MAX(IF(hh='20',order_count,0)) "20"
FROM
(
SELECT f.restaurant_name,
SUBSTR(p.time,1,2) hh,
COUNT(1) order_count
FROM food_orders f INNER JOIN payments p ON f.order_id=p.order_id
WHERE SUBSTR(p.time,1,2) BETWEEN 15 AND 20
GROUP BY 1,2
) a
GROUP BY 1
ORDER BY 7 desc무진장 길지만 저 MAX 함수를 써야한다. 왜냐하면 모든 최종값을 지정해줘야만 나오기 때문이다. 그래서 해당 값이 이렇게 나와야한다.
3. Window Function
이건 강의 설명만으로는 이해가 안가서 따로 구글링을 해서 좀 더 찾아봤다.
WINDOW FUCTION = 행과 행 간의 관계를 쉽게 정의하기 위해서 만들어진 함수
[EXCEL]에서 사용할 수 있는 일부 함수들을 좀 써볼 수 있었다. 다른 함수들과 중첩해서는 쓰지는 못하는 단점은 있지만, 서브쿼리문에 사용하는 등의 것은 가능한 듯 하다.
형식은 다음과 같다.
SELECT WINDOW_FUCTION (Arguments) OVER (PARTITION BY 칼럼 ORDER BY 칼럼, [WINDOWING 절])
FROM Data_tableWINDOW_FUNCITON = 윈도우 함수 기능 포함
ARGUMENTS(인수) : 0~N 개의 인수를 지정
PARTITION BY 칼럼 = 해당 칼럼을 분할하며
ORDER BY 칼럼 = 지정한 칼럼을 어떻게 순위를 정할지 배열한다.
TIP) WINDOWING 절 = 대상이 되는 행의 기준을 지정하는 것이나 SQL 의 서버는 지원하지 않는다고 한다.
사용가능한 함수 목록
[1] 그룹 내 순위 함수 : RANK, DENSE_RANK, ROW_NUMBER
[2] 그룹 내 집계 함수 : SUM, MAX, MIN, AVG, COUNT
[3] 행 순서 관련 함수 : FIRST_VALUE, LAST_VALUE, LAG, LEAG (ONLY 오라클)
[4] 비율 관련 함수 : CUME_DIST, PERCENT_RANK, NTILE, RATIO_TO_REPORT
[5] 통계 분석 함수
실습한 내용은 아예 이해가 안가서 다시 해보기로 했다.
SELECT price, RANK() OVER (ORDER BY price desc) 'ALL_RANK'
FROM food_orders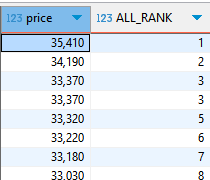
가격 중에서 모든 랭크를 쭉 내리면 다음과 같이 나온다.
이외에도 그룹내의 누적합과 합계도 동시에 구할 수 있다.
[실습 문제] 각 음식점의 주문건이 해당 음식 타입에서 차지하는 비율을 구하고, 주문건을 낮은 순으로 정렬하시오.
천천히 쿼리문을 작성해가면서 작성하기 시작했다.
- 필요한 칼럼 : 음식 타입, 식당 이름, 주문 건수
- 그룹별로 음식, 식당을 그룹으로서 표 만들기
SELECT cuisine_type, restaurant_name, count(1) order_count
FROM food_orders
GROUP BY 1,2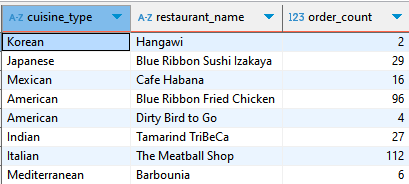
일단은 이 표가 서브쿼리로서 활약할 표 내용이다.
SELECT cuisine_type, restaurant_name,order_count
FROM
(
SELECT cuisine_type, restaurant_name, count(1) order_count
FROM food_orders
GROUP BY 1,2
) a
ORDER BY cuisine_type, order_count이렇게만 작성하면 각 식당별, 음식타입별의 주문 건수만 확인이 된다.
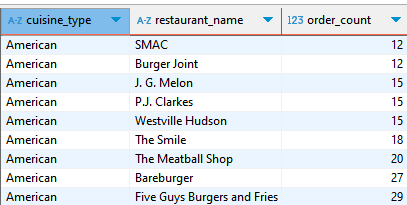
이제 누적 합계를 쓰기 시작하면 된다! 어떻게 쓸지 좀 고민을 하며 다시 해봐야할 듯 하다.
SELECT cuisine_type, restaurant_name,order_count,
SUM(order_count) OVER (PARTITION BY cuisine_type) sum_cuisine
FROM
(
SELECT cuisine_type, restaurant_name, count(1) order_count
FROM food_orders
GROUP BY 1,2
) a
ORDER BY cuisine_type, order_count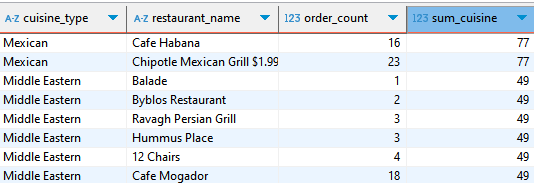
SUM 함수로 무엇을 한 상태냐면, order_count 의 칼럼을 세되, 이를 음식타입별로 나눠서 합계를 계산한다. 즉, 이 함수는 카테고리 별 합계이다.
그렇다면 누적합은 어떻게 해야할까?
SELECT cuisine_type, restaurant_name,order_count,
SUM(order_count) OVER (PARTITION BY cuisine_type) sum_cuisine,
SUM(order_count) OVER (PARTITION BY cuisine_type ORDER BY order_count) total_cuisine
FROM
(
SELECT cuisine_type, restaurant_name, count(1) order_count
FROM food_orders
GROUP BY 1,2
) a
ORDER BY cuisine_type, order_count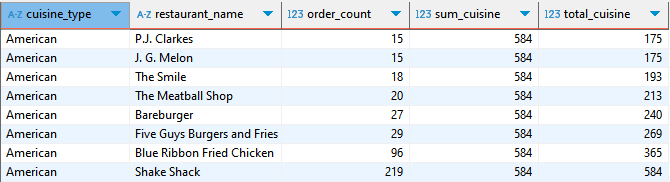
일단은 음식별로, 주문별로 정렬한 뒤 -> 카테고리별, 누적합계 모두 구한 표는 다음과 같이 나온다.
4. Date 함수
- 문자타입, 숫자타입 과 같은 날짜 데이터도 특정한 값이 나올 수 있다. 형식은 다음과 같다.
SELECT date(date) date_type, date
FROM 날짜값이 있는 테이블SELECT date(date) date_type,
date_format(date(date), '%Y') "년"
date_format(date(date), '%M') "월"
FROM paymentsdate_format 은 문자형의 date 포맷을 --> 날짜 형식으로 따로 바꿔주는 변환식이다.
DATE_FORMAT(날짜, 형식)날짜를 지정한 형식으로 출력하라는 지시문. 구분 기호는 다음과 같다.
| 구분 기호 | 역할 | 구분 기호 | 역할 |
| %Y | 4자리 년도 | %m | 숫자 월 (두자리) |
| %y | 2자리 년도 | %c | 숫자 월(한자리는 한자리) |
| %M | 긴 월(영문) | %d | 일자 (두자리) |
| %b | 짧은 월(영문) | %e | 일자(한자리는 한자리) |
| %W | 긴 요일 이름(영문) | %l | 시간(12시간) |
| %a | 짧은 요일 이름(영문) | %H | 시간(24시간) |
| %i | 분 | %r | hh:mm:ss AM,PM |
| %T | hh:mm:ss | %S | 초 |
[참조] - https://devjhs.tistory.com/89
[mysql] DATE_FORMAT - 날짜 형식 설정
1. DATE_FORMAT - 역할DATE_FORMAT(날짜 , 형식) : 날짜를 지정한 형식으로 출력 2. DATE_FORMAT - 구분기호 구분기호역할구분기호역할 %Y 4자리 년도 %m 숫자 월 ( 두자리 ) %y 2자리 년도 %c 숫자 월(한자리는 한
devjhs.tistory.com
오늘 일을 마무리하다보니 정말 배운게 많기도 했고, 강의를 들으면서 부족한 점이 많았다. 엑셀보다 쉬운 SQL 과 관련해서는 적어도 아는 수준만큼은 정리해본거 같고, 나머지는 코트카타 문제를 풀어보면서 오답을 정리하고, 새롭게 함수를 배우거나 해야할 듯 하다.
그리고 두번째로 파이썬과 관련된 함수열을 정리해보려고 한다. 왜냐면 알고리즘 코트카타를 공부하는 데 하나도 이해가 안되기 때문이다. 그래서 당분간은 코드카타를 공부하면서 오답 노트 정리를 좀 해보지 않을까 싶었다. 왜 안되는지 같은거..
그리고 저번부터 했던 아티클 스터디에 대해서도 좀 정리해보는 것도 좋을 거 같다. 이번 주는 '데이터 리터러시' 와 '데이터 분석의 오류'에 대한 글이었는데 확실히 데이터 분석에 있어서 좀 심도 있는 아티클이었기에 정리해두면 좋을 거 같아서...
일단은 오늘의 TIL 이만 마침!
'𝐓𝐈𝐋 (𝐅𝐨𝐫 𝐂𝐚𝐦𝐩) > 𝐂𝐎𝐃𝐈𝐍𝐆 (𝐒𝐐𝐋, 𝐏𝐘𝐓𝐇𝐎𝐍)' 카테고리의 다른 글
| [𝟐𝟓.𝟎𝟐.𝟐𝟖] 𝐓𝐈𝐋 𝐍𝐎𝐓𝐄 𝟗 (0) | 2025.02.28 |
|---|---|
| [𝟐𝟓.𝟎𝟐.𝟐𝟒] 𝐓𝐈𝐋 𝐍𝐎𝐓𝐄 𝟔 (1) | 2025.02.24 |
| [𝟐𝟓.𝟎𝟐.𝟏𝟗] 𝐓𝐈𝐋 𝐍𝐎𝐓𝐄 𝟒 (0) | 2025.02.19 |
| [𝟐𝟓.𝟎𝟐.𝟏𝟖] 𝐓𝐈𝐋 𝐍𝐎𝐓𝐄 𝟑 (0) | 2025.02.18 |
| [𝟐𝟓.𝟎𝟐.𝟏𝟕] 𝐓𝐈𝐋 𝐍𝐎𝐓𝐄 𝟐 (0) | 2025.02.17 |